



The event of synthetic intelligence has caused super developments in varied fields, however working AI fashions might be extremely resource-intensive, each financially and environmentally. AI fashions eat monumental quantities of electrical energy, and their vitality calls for are projected to develop as AI techniques change into extra advanced. For example, in early 2023, working ChatGPT consumed round 564 MWh of electrical energy per day, equal to the daily energy usage of 18,000 U.S. households.
This huge consumption is essentially attributable to AI fashions’ advanced computations, particularly floating-point operations in neural networks. These processes are inherently energy-hungry, involving heavy matrix operations and linear transformations. Nevertheless, a revolutionary new algorithm guarantees to considerably cut back this vitality load. It’s referred to as L-Mul (Linear-Complexity Multiplication), and it might reshape the way forward for AI by making fashions sooner and drastically extra energy-efficient.
Let’s discover L-Mul, the way it works, and what this implies for the way forward for energy-efficient AI.
Why AI is Vitality-Intensive
Neural networks are on the core of contemporary AI fashions, which use floating-point numbers to carry out computations. These floating-point operations are important for capabilities like matrix multiplications, that are vital to how neural networks course of and rework knowledge.
Neural networks usually use 32-bit and 16-bit floating-point numbers (referred to as FP32 and FP16) to deal with the parameters, inputs, and outputs. Nevertheless, floating-point multiplications are much more computationally costly than fundamental integer operations. Particularly, multiplying two 32-bit floating-point numbers consumes roughly 4 occasions the vitality required so as to add two FP32 numbers and 37 occasions extra vitality than including two 32-bit integers.
Thus, floating-point operations current a big vitality bottleneck for AI fashions. Lowering the variety of these floating-point multiplications with out sacrificing efficiency can tremendously improve AI techniques’ vitality effectivity.
The Delivery of L-Mul: An Vitality-Saving Resolution
That is the place the L-Mul algorithm steps in. Developed by researchers and recently published on ArXiv, L-Mul simplifies floating-point multiplications by approximating them with integer additions. The important thing benefit? This algorithm might be seamlessly built-in into current AI fashions, eliminating the necessity for fine-tuning and enabling substantial vitality financial savings.
By changing advanced floating-point multiplications with a lot less complicated integer additions, L-Mul achieves as much as 95% vitality discount for element-wise tensor multiplications and saves as much as 80% vitality for dot product computations. This vitality effectivity doesn’t come at the price of accuracy both, making L-Mul a breakthrough for working AI fashions with minimal energy consumption.
Understanding Floating-Level Operations
To higher recognize the affect of L-Mul, let’s take a more in-depth take a look at the floating-point operations on which AI fashions rely. If you multiply two floating-point numbers, the method entails:
-
Exponent addition (O(e) complexity)
-
Mantissa multiplication (O(m²) complexity)
-
Rounding and normalization
The mantissa multiplication is probably the most resource-intensive a part of this course of, requiring important computational energy, which results in excessive vitality consumption. Then again, integer addition is way less complicated and fewer energy-intensive, with a linear complexity of O(n), the place n represents the bit measurement of the integers concerned.
How L-Mul Works: Changing Floating-Level Multiplications
The L-Mul algorithm simplifies this course of by changing floating-point mantissa multiplications with integer additions. Right here’s the way it works:
-
Two floating-point numbers (x and y) are represented by their mantissas (the fractional components) and exponents.
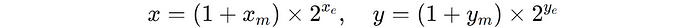
-
As an alternative of performing costly mantissa multiplication, L-Mul makes use of integer additions to approximate the outcome.
-
If the mantissa sum exceeds 2, the carry is added on to the exponent, skipping the necessity for normalization and rounding present in conventional floating-point multiplication.
This method reduces the time complexity from O(m²) (for mantissa multiplication) to O(n), the place n is the bit measurement of the floating-point quantity, making it much more environment friendly.
Precision vs. Computational Effectivity
Along with being energy-efficient, L-Mul gives a excessive diploma of precision. As AI fashions more and more undertake 8-bit floating-point numbers (FP8) to cut back reminiscence utilization and computational value, L-Mul shines as a extremely efficient different. FP8 has two frequent representations: FP8_e4m3 (extra exact however with a smaller vary) and FP8_e5m2 (much less exact however with a bigger vary).
When in comparison with FP8, L-Mul outperforms when it comes to each precision and computational effectivity. L-Mul gives better precision than FP8_e4m3 whereas consuming fewer computational sources than FP8_e5m2, making it a superior different in lots of situations.
Actual-World Functions of L-Mul
So, how does L-Mul carry out in real-world AI duties? Let’s break it down:
Transformer Fashions and LLMs
L-Mul might be immediately utilized to transformer fashions, notably within the attention mechanism, the place large-scale matrix multiplications happen. This utility results in as much as 80% vitality financial savings with out sacrificing efficiency. No fine-tuning is required, which is a big benefit.
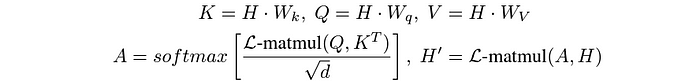
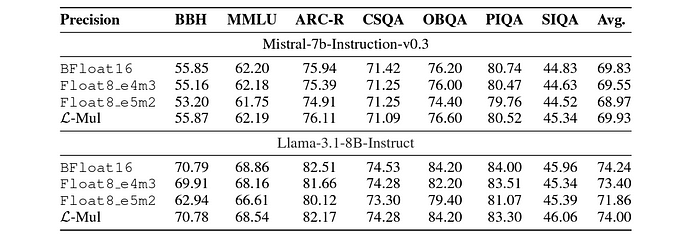
For example, in massive language fashions (LLMs) like Mistral-7b and Llama-3.1, L-Mul has been proven to outperform FP8 and Bfloat16, frequent floating-point codecs utilized in transformers, throughout varied benchmarks, together with text-based and instruction-following duties.
GSM8k and Different Benchmarks
When evaluated on particular duties like GSM8k, which exams fashions on grade-school math issues, L-Mul constantly outperformed FP8 when it comes to accuracy and effectivity. This demonstrates that L-Mul can deal with advanced mathematical reasoning with out requiring extreme computational energy.

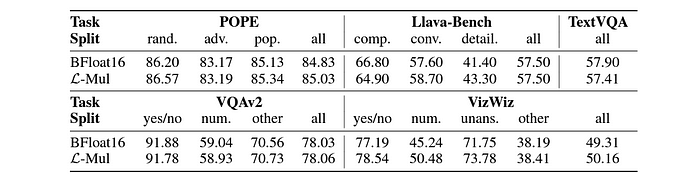
Visible Query Answering (VQA) and Object Detection
In fashions like Llava-v1.5–7b, that are used for visible query answering and object hallucination, L-Mul once more surpassed FP8 in each accuracy and computational effectivity, reaffirming its utility in multimodal duties that require a mixture of textual content and picture processing.
What the Future Holds for L-Mul
The power to make use of L-Mul with out fine-tuning and its exceptional vitality financial savings implies that it might change into a key participant in the way forward for AI improvement. It’s already clear that this algorithm can improve the efficiency of fashions throughout a number of domains, from language processing to imaginative and prescient duties, all whereas lowering the carbon footprint related to AI computations.
The outcomes are simply as promising in fashions the place fine-tuning is required. When examined on the Gemma2–2b-It mannequin, L-Mul carried out on the identical stage as FP8_e4m3, which means that even fine-tuned fashions can preserve their accuracy whereas turning into extra energy-efficient.
The way forward for AI is brilliant, however it additionally must be sustainable. With algorithms like L-Mul, we’re on the trail to creating smarter, sooner, and greener AI techniques.
Conclusion: A New Period of Vitality-Environment friendly AI
The L-Mul algorithm represents an enormous leap ahead in creating energy-efficient AI. By changing costly floating-point multiplications with less complicated integer additions, L-Mul reduces energy consumption and improves computational effectivity and mannequin efficiency throughout the board.
As AI advances and calls for extra computational energy, options like L-Mul will probably be essential for guaranteeing that progress doesn’t come at an unsustainable value to the atmosphere.
Reference Studying
FAQs
-
What’s L-Mul?
L-Mul stands for Linear-Complexity Multiplication, an algorithm that replaces floating-point multiplications with integer additions to enhance vitality effectivity in AI fashions.
-
How does L-Mul save vitality in AI computations?
L-Mul simplifies the expensive floating-point operations in neural networks, lowering vitality consumption by as much as 95% for tensor multiplications and 80% for dot merchandise.
-
Does L-Mul have an effect on the accuracy of AI fashions?
No, L-Mul maintains the accuracy of AI fashions whereas lowering their vitality consumption, making it a great selection for energy-efficient AI techniques.
-
Can L-Mul be built-in into current AI fashions?
Sure, L-Mul might be seamlessly built-in into current neural networks with none want for fine-tuning, making it a sensible resolution for enhancing vitality effectivity.
-
How does L-Mul evaluate to FP8 in AI duties?
L-Mul outperforms FP8 in each precision and computational effectivity, making it a superior different for a lot of AI functions.
You might also like



More from Web3

Robinhood Launches ‘AI-Native’ Ethereum Layer-2 Network, Tokenized Stock Trading
In short Robinhood launched the general public mainnet of Robinhood Chain, an "AI-native" Ethereum layer-2 community. The chain additional bridges the …

Venice AI Valued at $1 Billion as Erik Voorhees Makes the Case for Private ChatGPT Rivals
In short Venice AI raised $65 million at a $1 billion valuation in its first exterior funding spherical. Founder Erik Voorhees …

Morning Minute: Major New Stablecoin Launch Shakes Incumbents
Morning Minute is a day by day e-newsletter written by Tyler Warner. The evaluation and opinions expressed are his personal …


