



LM Studio vs. Ollama
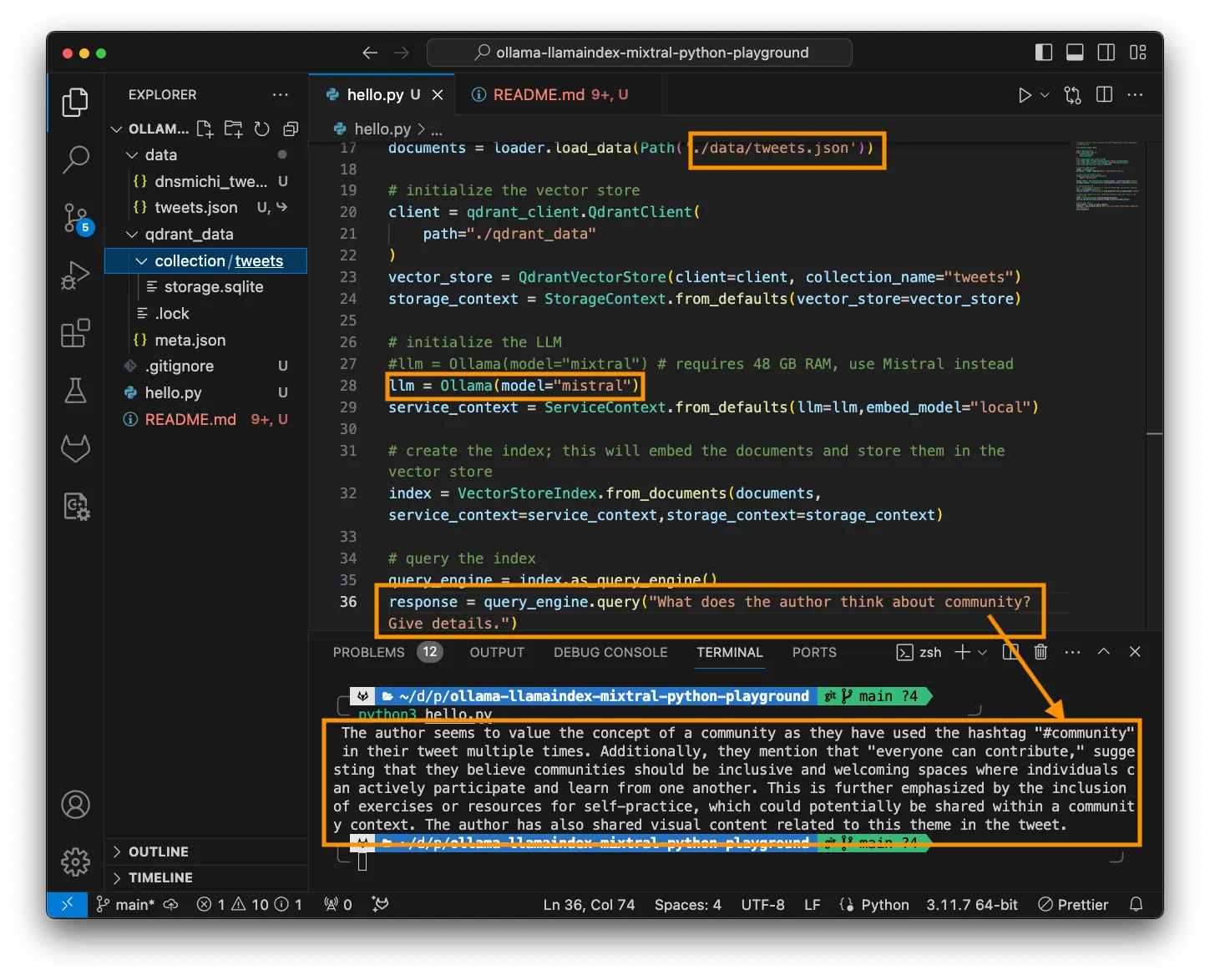
Organising LM Studio
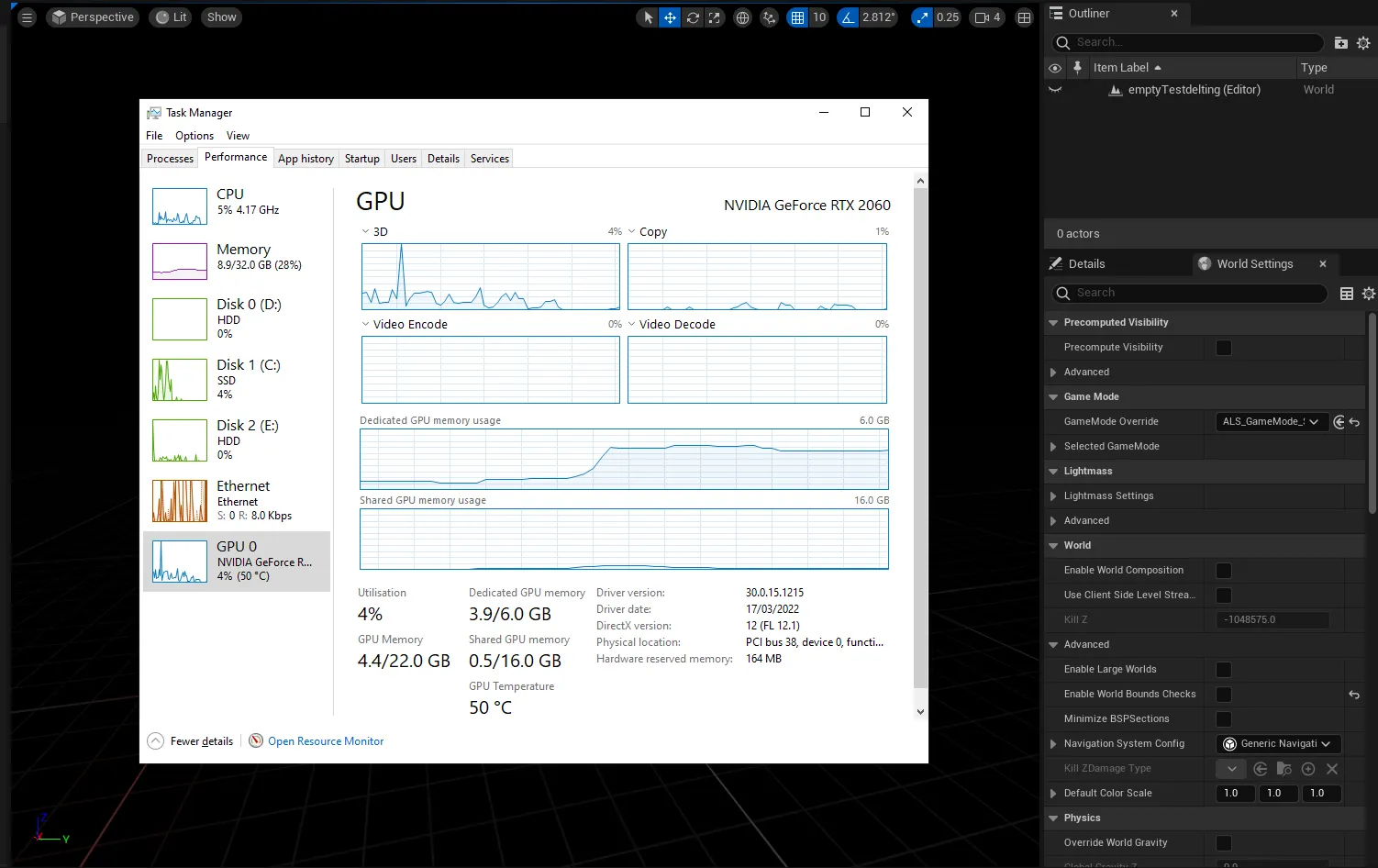
VRAM: The important thing to working native AI

Downloading your fashions
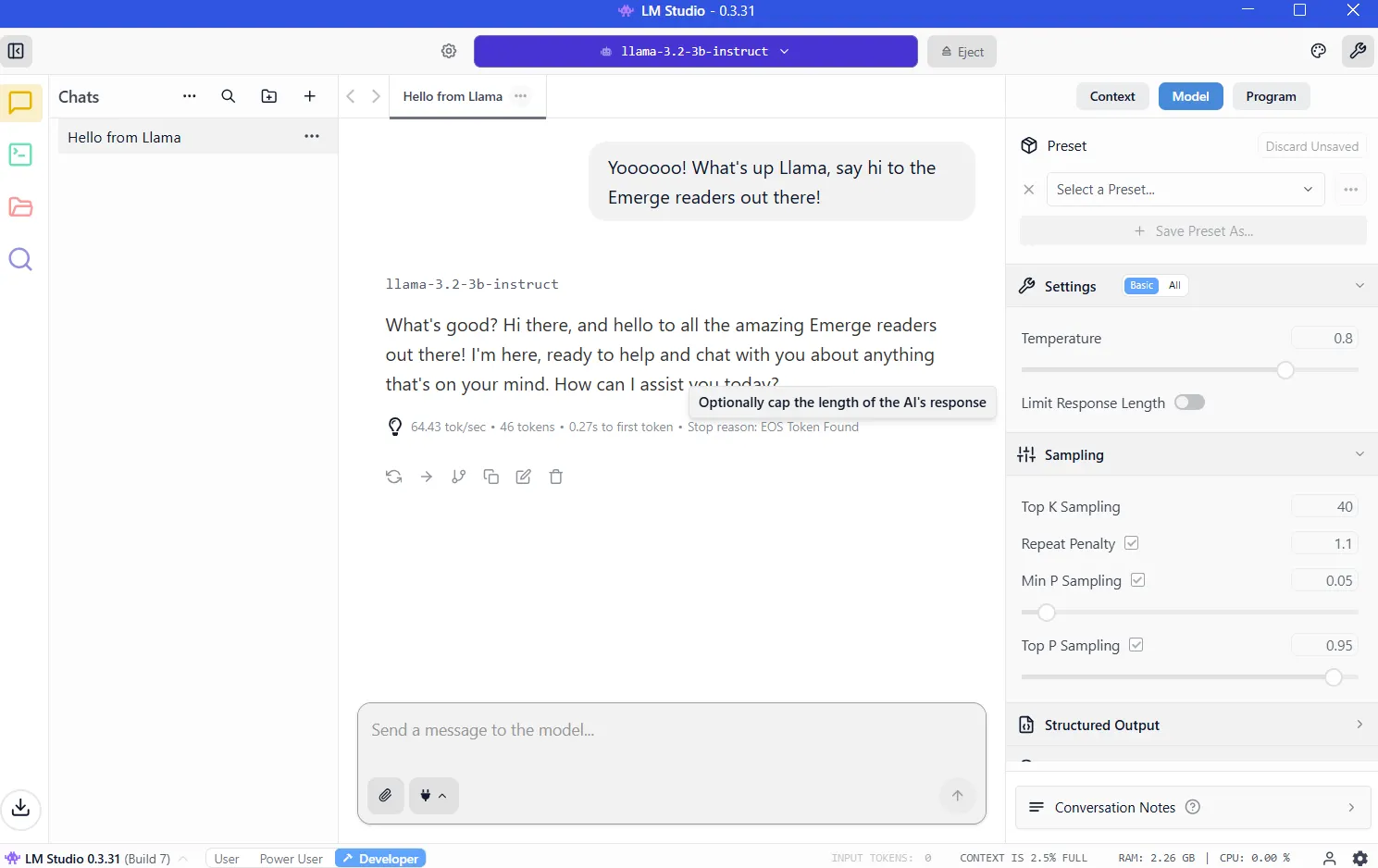
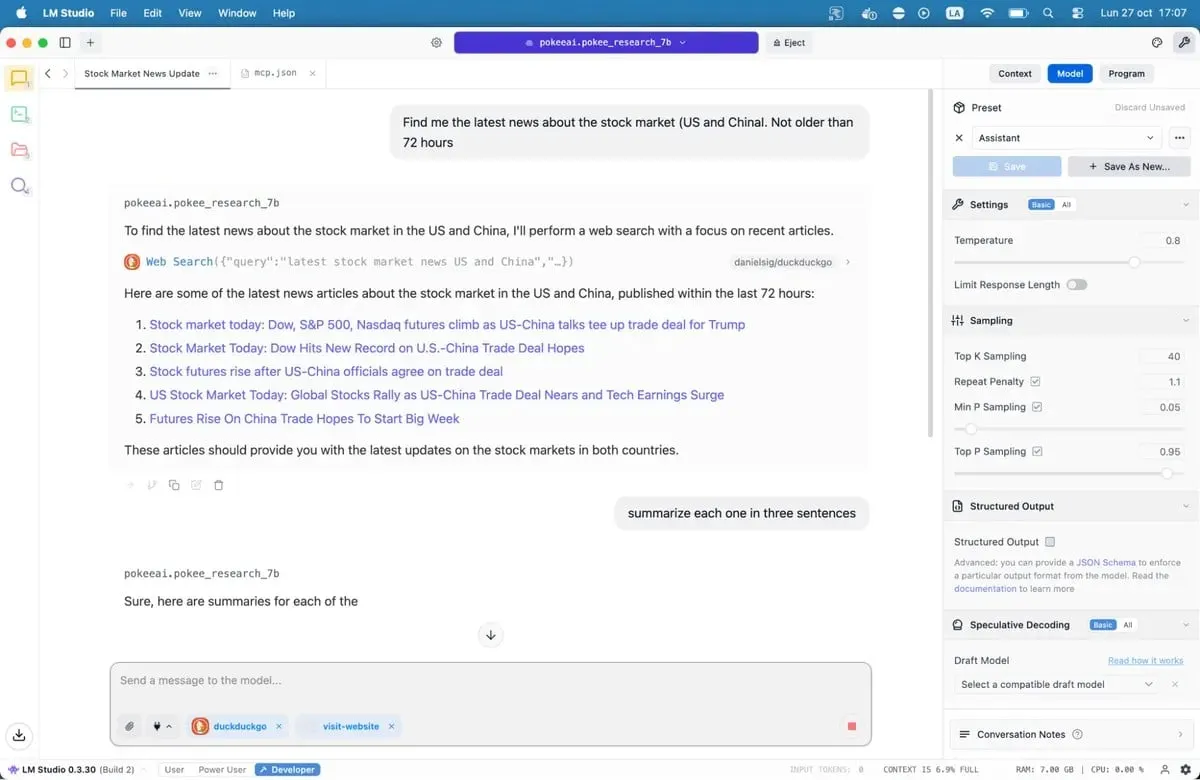
Giving your mannequin web entry
Our beneficial fashions for 8GB programs
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.
You might also like



More from Web3

Turkey Soft Skills Training Market Outlook: Trends, Growth, and Future Opportunities 2026-2034
The Turkey Gentle Abilities Coaching Market was valued at USD 326.24 Million in 2025 and is projected to …

Democrats Press Meta Over Facial Recognition Plans for Smart Glasses
In short Democratic senators are warning real-time facial identification may expose people to stalking, harassment, and focused intimidation. Prior reporting this …

Industrial Furnace Market to Surge to USD 17.01 Billion by 2031 Driven by Steel, Automotive, and Manufacturing Demand
Industrial Furnace Market Mordor Intelligence has printed a brand new report on the Industrial furnace market, providing a complete …


 bespoke shoemakers I have known")