



One of the persistent challenges has been understanding precisely how massive language fashions (LLMs) like ChatGPT and Claude work. Regardless of their spectacular capabilities, these subtle AI programs have largely remained “black packing containers”—we all know they produce exceptional outcomes, however the exact mechanisms behind their operations have been shrouded in thriller—that’s, till now.
A groundbreaking analysis paper revealed by Anthropic in early 2025 has begun to carry this veil, providing unprecedented insights into the internal workings of those complicated programs. The analysis would not simply present incremental data – it essentially reshapes our understanding of how these AI fashions assume, purpose, and generate responses. Let’s dive deep into this fascinating exploration of what is likely to be known as “the anatomy of the AI thoughts.”
Understanding the Foundations: Neural Networks and Neurons
Earlier than we are able to admire the breakthroughs in Anthropic’s analysis, we have to set up foundational data in regards to the construction of recent AI programs.
At their core, at present’s most superior AI fashions are constructed upon neural networks – computational programs loosely impressed by the human mind. These neural networks include interconnected parts known as “neurons” (although the technical time period is “hidden models”). Whereas the comparability to organic neurons is imperfect and considerably deceptive to neuroscientists, it offers a helpful conceptual framework for understanding these programs.
Giant language fashions like ChatGPT, Claude, and their counterparts are basically huge collections of those neurons working collectively to carry out a seemingly easy activity: predicting the following phrase in a sequence. Nonetheless, this simplicity is misleading. Fashionable frontier fashions include a whole lot of billions of neurons interacting in terribly complicated methods to make these predictions.
The sheer scale and complexity of those interactions have made it exceptionally obscure precisely how these fashions arrive at their solutions. Not like conventional software program, the place builders write specific directions that this system follows, neural networks develop their inside processes by means of coaching on huge datasets. The result’s a system that produces spectacular outputs however whose inside mechanisms have remained largely opaque.
The Downside of Polysemantic Neurons
Early makes an attempt to grasp these fashions targeted on analyzing particular person neuron activations – basically monitoring when particular neurons “fireplace” in response to explicit inputs. The hope was that particular person neurons may correspond to particular ideas or matters, making the mannequin’s habits interpretable.
Nonetheless, researchers shortly encountered a big impediment: neurons in these fashions turned out to be “polysemantic,” that means they might activate in response to a number of, seemingly unrelated matters.
This polysemantic nature made it exceedingly tough to map particular person neurons to particular ideas or to foretell a mannequin’s habits based mostly on which neurons have been activating. The fashions remained black packing containers, and their inside workings have been proof against easy interpretation.
The Function Discovery Breakthrough
The primary main breakthrough in understanding these programs got here when Anthropopic researchers found that whereas particular person neurons is likely to be polysemantic, particular combos of neurons have been usually “monosemantic “—uniquely related to specific concepts or outcomes.
This perception led to the event of the idea of “options” – explicit patterns of neuron activation that might be reliably mapped to particular matters or behaviors. Relatively than making an attempt to grasp the mannequin on the stage of particular person neurons, researchers may now analyze it by way of these characteristic activations.
To facilitate this evaluation, Anthropic launched a strategy known as “sparse autoencoders” (SAEs), which helped determine and map these neuron circuits to particular options. This method remodeled what was as soon as an impenetrable black field into one thing extra akin to a map of options explaining the mannequin’s data and habits.
Maybe much more considerably, researchers found they might “steer” a mannequin’s habits by artificially activating or suppressing the neurons related to explicit options. By “clamping” sure options – forcing the related neurons to activate strongly – they might produce predictable behaviors within the mannequin.
In a single hanging instance, by clamping the characteristic related to the Golden Gate Bridge, researchers may trigger the mannequin to basically behave as if it have been the bridge itself, producing textual content from the attitude of the long-lasting San Francisco landmark.
Function Graphs: The New Frontier
Constructing on these earlier discoveries, Anthropic’s latest research introduces the concept of “characteristic graphs,” which takes mannequin interpretability to new heights. Relatively than making an attempt to map the billions of neuron activations on to outputs, characteristic graphs remodel these complicated neural patterns into extra understandable representations of ideas and their relationships.
To grasp how this works, think about a easy instance: When a mannequin is requested, “What’s the capital of Texas?” The anticipated reply is “Austin.” In conventional approaches to understanding the mannequin, we would wish to research billions of neuron activations to grasp how the mannequin arrived at this reply—an successfully not possible activity.
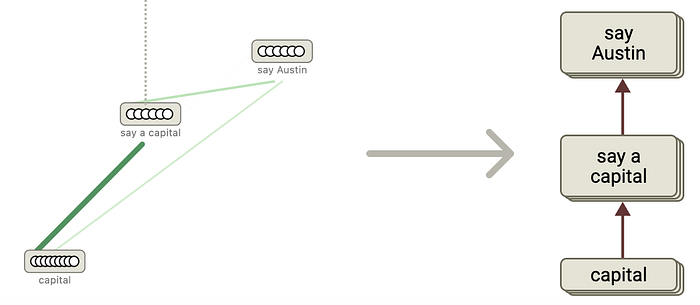
However characteristic graphs present one thing exceptional: When the mannequin processes the phrases “Texas” and “capital,” it prompts neurons associated to those ideas. The “capital” neurons promote a set of neurons answerable for outputting a capital metropolis title. Concurrently, the “Texas” neurons present context. These two activation patterns then mix to activate the neurons related to “Austin,” main the mannequin to supply the proper reply.
This represents a profound shift in our understanding. For the primary time, we are able to hint a transparent, interpretable path from enter to output by means of the mannequin’s inside processes. LLM outputs are now not mysterious; they’ve a mechanistic rationalization.
Past Memorization: Proof of Reasoning
At this level, it could be straightforward to take a cynical stance and argue that these circuits merely symbolize memorized patterns fairly than real reasoning. In any case, could not the mannequin simply be retrieving the memorized sequence “Texas capital? Austin” fairly than performing any actual inference?
What makes Anthropic’s findings so vital is that they exhibit these circuits are literally generalized and adaptable – qualities that counsel one thing extra subtle than easy memorization.
For instance, if researchers artificially suppress the “Texas” characteristic whereas holding the “capital” characteristic lively, the mannequin will nonetheless predict a capital metropolis – simply not Texas’s capital. The researchers may management which capital the mannequin produced by activating neurons representing completely different states, areas, or nations, whereas nonetheless using the identical fundamental circuit structure.
This adaptability strongly means that what we’re seeing is not rote memorization however a type of generalized data illustration. The mannequin has developed a common circuit for answering questions on capitals and adapts that circuit based mostly on the particular enter it receives.
Much more compelling proof comes from the mannequin’s capability to deal with multi-step reasoning duties. When prompted with a query like “The capital of the state containing Dallas is…”, the mannequin engages in a multi-hop activation course of:
-
It acknowledges the phrases “capital” and “state,” activating neurons that promote capital metropolis predictions
-
In parallel, it prompts “Texas” after processing “Dallas”
-
These activations mix – the urge to supply a capital title and the context of Texas – ensuing within the prediction of “Austin”
This activation sequence bears a hanging resemblance to how a human may purpose by means of the identical query, first figuring out that Dallas is in Texas, then recalling that Austin is Texas’s capital.
Planning Forward: The Autoregressive Paradox
Maybe one of the stunning discoveries in Anthropic’s analysis issues the flexibility of those fashions to “plan forward” regardless of their basic architectural constraints.
Giant language fashions like GPT-4 and Claude are autoregressive, that means they generate textual content one token (roughly one phrase) at a time, with every prediction based mostly solely on the tokens that got here earlier than it. Given this structure, it appears counterintuitive that such fashions may plan past the speedy subsequent phrase.
But Anthropic’s researchers noticed precisely this type of planning habits in poetry era duties. When writing poetry, a specific problem is making certain that the ultimate phrases of verses rhyme with one another. Human poets usually handle this by planning the rhyming phrase on the finish of a line first, then developing the remainder of the road to guide naturally to that phrase.
Remarkably, the neural characteristic graphs revealed that LLMs make use of the same technique. As quickly because the mannequin processes a token indicating a brand new line of poetry, it begins activating neurons related to phrases that may make each semantic sense and rhyme appropriately – a number of tokens earlier than these phrases would truly be predicted.
In different phrases, the mannequin is planning the end result of all the verse earlier than producing a single phrase of it. This planning capability represents a complicated type of reasoning that goes effectively past easy sample matching or memorization.
The Common Circuit: Multilingual Capabilities and Past
The analysis uncovered further fascinating capabilities by means of these characteristic graphs. For example, fashions exhibit “multilingual circuits” – they perceive consumer requests in a language-agnostic kind, utilizing the identical fundamental circuitry to reply whereas adapting interchangeably to the enter language.
Equally, for mathematical operations like addition, fashions seem to make use of memorized outcomes for easy calculations however make use of elaborate circuits for extra complicated additions, producing correct outcomes by means of a course of that resembles step-by-step calculation fairly than mere retrieval.
The analysis even paperwork complicated medical prognosis circuits, the place fashions analyze reported signs, use them to advertise follow-up questions, and elaborate on appropriate diagnoses by means of multi-step reasoning processes.
Implications for AI Improvement and Understanding
The importance of Anthropic’s findings extends far past tutorial curiosity. These discoveries have profound implications for the way we develop, deploy, and work together with AI programs.
First, the proof of generalizable reasoning circuits offers a powerful counter to the narrative that enormous language fashions are merely “stochastic parrots” regurgitating memorized patterns from their coaching information. Whereas memorization undoubtedly performs a big function in these programs’ capabilities, the analysis clearly demonstrates behaviors that transcend easy memorization:
-
Generalizability: The circuits recognized are common and adaptable, utilized by fashions to reply comparable but distinct questions. Relatively than growing distinctive circuits for each attainable immediate, fashions summary key patterns and apply them throughout completely different contexts.
-
Modularity: Fashions can mix completely different, less complicated circuits to develop extra complicated ones, tackling tougher questions by means of composition of fundamental reasoning steps.
-
Interventability: Circuits might be manipulated and tailored, making fashions extra predictable and steerable. This has huge implications for AI alignment and security, doubtlessly permitting builders to dam sure options to stop undesired behaviors.
-
Planning capability: Regardless of their autoregressive structure, fashions exhibit the flexibility to plan forward for future tokens, altering present predictions to allow particular desired outcomes later within the sequence.
These capabilities counsel that whereas present language fashions might not possess human-level reasoning, they’re engaged in behaviors that actually transcend mere sample matching – behaviors that might moderately be characterised as a primitive type of reasoning.
The Path Ahead: Challenges and Alternatives
Regardless of these thrilling discoveries, vital questions stay in regards to the future improvement of AI reasoning capabilities. The present capabilities emerged after coaching on trillions of information factors, but stay comparatively primitive in comparison with human reasoning. This raises issues in regards to the viability of enhancing these capabilities inside present paradigms.
Will fashions ever develop really human-level reasoning capabilities? Some specialists counsel that we may have basic algorithmic breakthroughs that enhance information effectivity, permitting fashions to be taught extra from much less information. With out such breakthroughs, there is a danger that these fashions may plateau of their reasoning talents.
However, the brand new understanding supplied by characteristic graphs opens thrilling potentialities for extra managed and focused improvement. By understanding precisely how fashions purpose internally, researchers may have the ability to design coaching methodologies that particularly improve these reasoning circuits, fairly than counting on the present method of huge coaching on various information and hoping for emergent capabilities.
Moreover, the flexibility to intervene in particular options opens new potentialities for AI alignment – making certain fashions behave in accordance with human values and intentions. Relatively than treating alignment as a black-box downside, builders may have the ability to straight manipulate the particular circuits answerable for doubtlessly problematic behaviors.
Conclusion: A New Period of AI Understanding
Anthropic’s analysis represents a watershed second in our understanding of synthetic intelligence. For the primary time, now we have concrete, mechanistic proof of how massive language fashions course of info and generate responses. We will hint the activation of particular options by means of the mannequin, watching because it combines ideas, makes inferences, and plans.
Whereas these fashions nonetheless rely closely on memorization and sample recognition, the analysis conclusively demonstrates that there is extra to their capabilities than these easy mechanisms. Figuring out generalizable, modular reasoning circuits offers compelling proof that these programs are participating in processes that, whereas not similar to human reasoning, actually transcend easy retrieval.
As we proceed to develop extra highly effective AI programs, this deeper understanding shall be essential for addressing issues about security, alignment, and the last word capabilities of those applied sciences. Relatively than flying blind with more and more highly effective black packing containers, we now have instruments to look inside and perceive the anatomy of the AI thoughts.
The implications of this analysis prolong past technical understanding – they contact on basic questions in regards to the nature of intelligence itself. If seemingly easy neural networks can develop primitive reasoning capabilities by means of publicity to patterns in information, what does this inform us in regards to the nature of human reasoning? Are there deeper info processing ideas that underlie organic and synthetic intelligence?
These questions stay open, however Anthropic’s analysis has given us highly effective new exploration instruments. As we proceed to map the anatomy of synthetic minds, we might achieve surprising insights into our personal.
You might also like


 Market Forecast to Reach USD 23.74 Billion by 2033, Driven by 5G Rollout and Shift Toward Software-Defined Networks")
More from Web3

MLB Signs Exclusive Polymarket Deal, ‘Integrity Framework’ Agreement With CFTC
In short MLB named Polymarket its official prediction market associate, with unique entry to branding and information, centered round a …

ACCESS Newswire Reports Fourth Quarter and Full Year 2025 Results
Elevated ARR Results in Greater Gross Margins and Adjusted EBITDAThis fall 2025 income grew modestly to $5.8M in comparison …

Nasdaq Wins SEC Approval to Trade Tokenized Securities in Pilot Program
Briefly The plan covers Russell 1000 shares and a few index ETFs at launch, with the identical rights, symbols, and …


